Neural Style Transfer em imagens
Em uma das matérias da pós, Deep Learning Aplicado à Imagens, tivemos que fazer a apresentação de um trabalho sobre Neural Style Transfer, e notamos que existem poucos artigos em português sobre o assunto, e alguns muito rasos. Resolvi então colocar a nossa apresentação powerpoint no papel, e escrever este artigo com informações mais específicas sobre o paper que criou esse conceito de Transferência de Estilo em Imagens, utilizando Redes Neurais Convolucionais. Não vou entrar em conceitos muito profundos sobre os cálculos realizados, para isso sugiro a leitura do paper, que não é uma leitura pesada.
Introdução
Uma das aplicações mais legais do deep learning é o Neural Style Transfer em imagens. Através desse sistema de inteligência artificial, é possível separar as representações de conteúdo e estilo de duas imagens, e combiná-los, de maneira a formar uma terceira imagem, com o conteúdo de uma, e o estilo da outra. Este sistema foi apresentado inicialmente no artigo A Neural Algorithm of Artistic Style (arXiv:1508.06576), publicado por Gatys, Ecker, e Bethge na Universidade de Tübingen em Agosto de 2015.
Neste post apresento uma tradução/explicação do artigo original.

Foto da cidade de Tubingen (Fonte)
As melhores redes neurais profundas para processamento de imagens são as Redes Neurais Convolucionais (CNN). Essas redes possuem diversas camadas aninhadas que processam a informação visual da imagem. Cada camada da rede é composta por uma coleção de filtros de imagem, onde cada um desses filtros extrai uma determinada característica da imagem de entrada. Esses outputs de uma camada são chamados de feature maps, esses mapas de características formam uma representação da imagem.
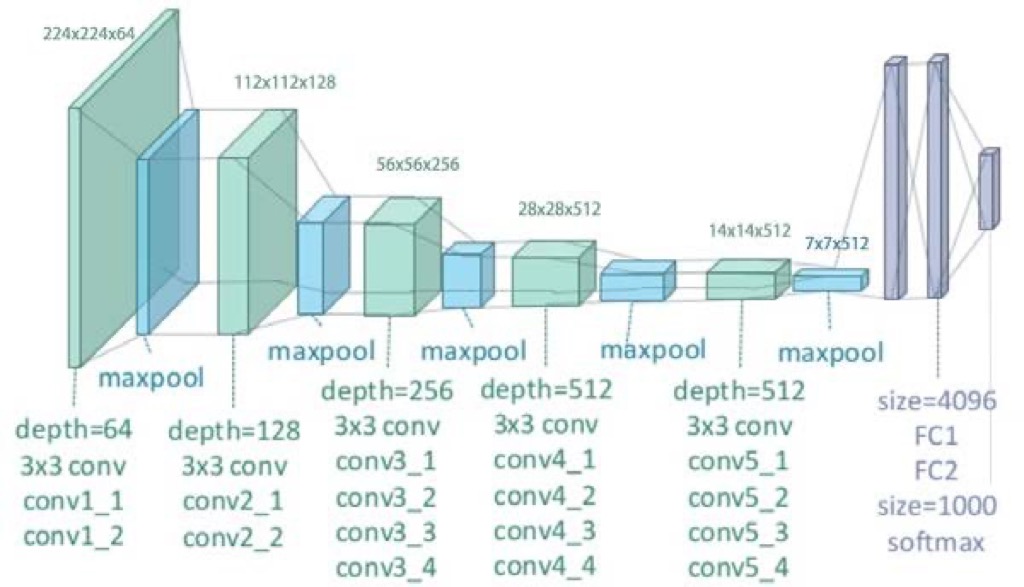
Representação visual da VGG19 (Fonte)
Como funciona
Como Gatys, Ecker e Bethge citam em seu artigo, quando as CNN são treinadas para reconhecimento de objetos, elas desenvolvem uma representação da imagem que deixa a informação dos objetos mais explícita conforme vai se aprofundando na hierarquia da rede. Portanto, durante o processamento da rede, a imagem de entrada é transformada em representações que cada vez mais definem o conteúdo da imagem de uma forma geral, ao invés de manter os valores individuais dos pixels. Com base nessas informações, é possível visualizar essa representação, reconstruindo a imagem a partir de seus feature maps, como pode ser observado nos exemplos abaixo.
Reconstruíndo o Conteúdo
Os níveis mais profundos da rede capturam a informação em alto nível, não mantendo os valores exatos de cada pixel na reconstrução (exemplos d e e). Já as camadas iniciais da rede, retém mais informação específica de cada pixel, mantendo uma estrutura mais fiel à imagem original (exemplos a, b e c).
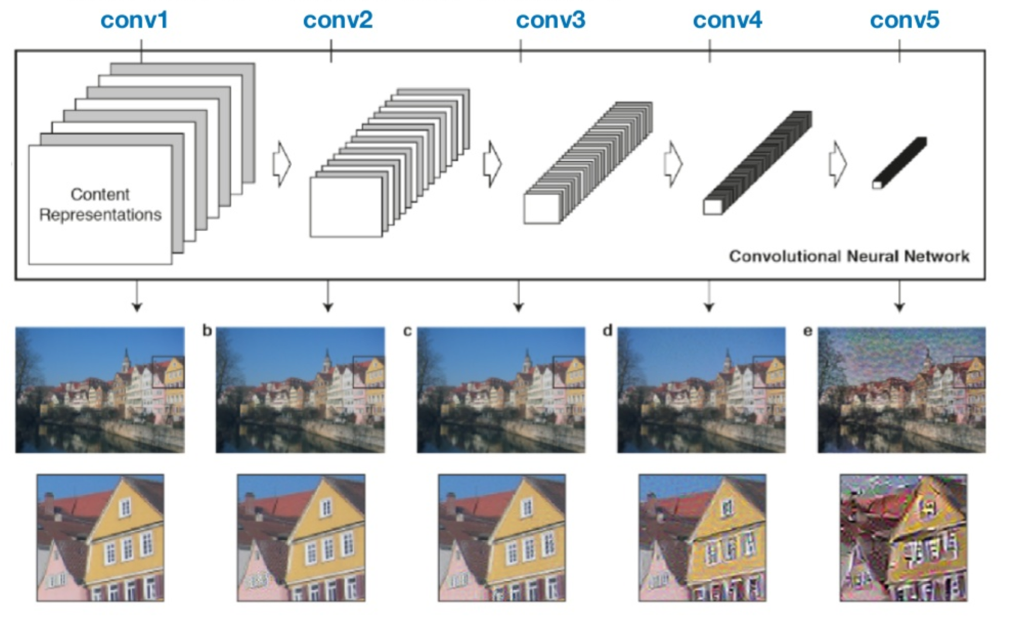 Reconstrução da Imagem de Conteúdo através dos diferentes feature maps
Reconstrução da Imagem de Conteúdo através dos diferentes feature maps
Reconstruíndo o Estilo
A representação do estilo da imagem é recriado a partir da correlação entre diferentes features de diferentes camadas da CNN. Na imagem abaixo podem ser vistas essas representações de estilo, utilizando diferentes camadas. Podemos observar que com apenas uma camada, a representação fica mais simples, focando apenas nas cores, mas conforme são adicionadas camadas, aumenta a representatividade do estilo na forma de textura e cores da imagem, sem nunca recriar a imagem original. No exemplo posterior, no código, será utilizado o exemplo e, que é a junção de 5 camadas da CNN: conv1_1, conv2_1, conv3_1, conv4_1 and conv5_1.
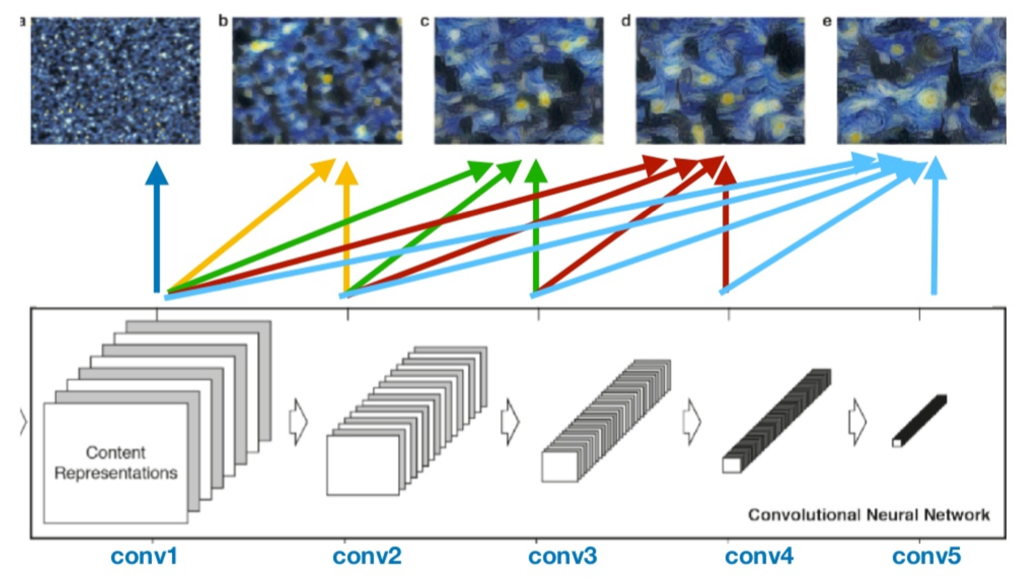 Reconstrução da Imagem de Estilo através dos diferentes feature maps
Reconstrução da Imagem de Estilo através dos diferentes feature maps
Criando a imagem estilizada
Um dos pontos principais descoberto por esse paper, foi descobrir que conteúdo e estilo de uma imagem podem ser separados em uma rede convolucional. E com essas representações separadas, essas informações podem ser manipuladas, de maneira a criar uma terceira imagem, que combine o estilo de uma imagem, com o conteúdo de outra. Para demonstrar essas descobertas, os autores do artigo criaram diferentes imagens daquela foto da cidade de Tübingen, nos estilo de diferentes obras de arte. Pode-se perceber nesses exemplos que o arranjo geral da imagem é formado pela foto de conteúdo, e as cores e texturas são oriúndas das obras de arte.
 Cidade de Tübingen em diferentes estilos
Cidade de Tübingen em diferentes estilos
Intuição
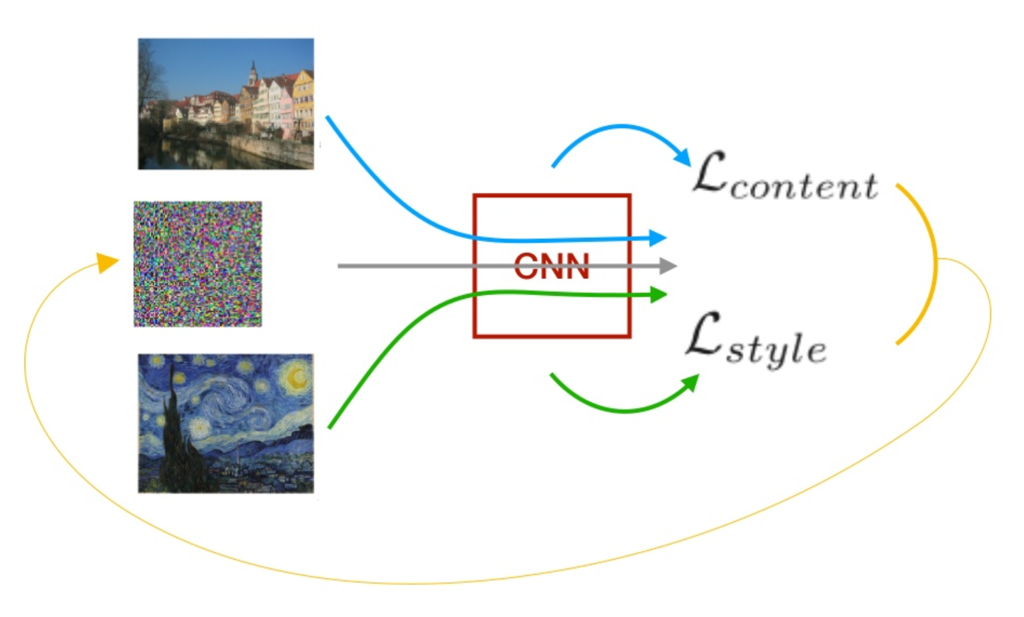
Obviamente, o conteúdo e estilo de uma imagem não podem ser completamente separados. Ao aplicar esse processo de transferência de estilo, não é possível criar uma imagem que combine perfeitamente o conteúdo de uma imagem e o estilo da outra sem alguma perda. Para a criação da imagem final, o algoritmo proposto pelos autores realiza uma minimização de uma função de custo para o conteúdo e o estilo.
São duas funções de custo diferentes, minimizadas conjuntamente em uma única função geral, com o objetivo de encontrar a menor distância entre as representações das imagens originais e a imagem gerada. Esse processo é rodado repetidamente, durante X iterações, tentando minimizar o encontrar o menor valor possível. A medida utilizada para calcular essa função de custo, é a média-quadrada da distância entre a Matriz de Gram da imagem original e da imagem gerada.
Custo de Conteúdo + Custo de Estilo = Custo Total
 Função de Custo
Função de Custo
É possível regular a ênfase do algorítmo para reconstruir o conteúdo, ou o estilo. Uma ênfase maior no estilo vai criar imagens mais parecidas com a imagem de estilo original, gerando uma imagem com a textura mais parecida com ela, mas com menos semelhanças à imagem de origem do conteúdo. Quando a ênfase é no conteúdo, claramente é possível identificar a fotografia de origem, mas ficará com menos influência do estilo.
 Diferentes pesos para estilo e conteúdo
Diferentes pesos para estilo e conteúdo
Há também uma possibilidade de configurar a imagem de output com uma inicialização diferente, e com isso afetar o resultado final. Na imagem abaixo podemos ver esses resultados na inicialização da transferência de estilo.
 Pontos de Inicialização Diferentes: ESTILO / CONTEÚDO / NOISE. Fonte
Pontos de Inicialização Diferentes: ESTILO / CONTEÚDO / NOISE. Fonte
No resultado da esquerda, a inicialização com a imagem de estilo, no centro, a inicialização com a imagem de conteúdo, e na direita inicialização com a imagem de noise. Pode-se perceber a diferença entre as imagens, cada uma gerando um resultado mais parecido com o seu ponto de inicialização.
Mãos na massa!
No link abaixo vocês podem verificar um exemplo de código funcionando no Google Colab, realizando essa tarefa de Transferência de Estilo em Imagens, utilizando o Tensorflow e a VGG19. Apenas levem em consideração que as fotos do meu bigode são as imagens de conteúdo, o estilo é todo meu. :-P
Notebook de exemplo Neural Style Transfer
Existem bons materiais em português também, e deixo dois links que eu considerei boas referências:
- CNN — Como fazer uma Transferência de Estilo facilmente
- Neural Style Transfer usando Redes Neurais Convolucionais
Referências

Sobre o Autor: William Becher
Engenheiro de Dados com experiência em Big Data, Cloud Computing e DevOps. Compartilhando aprendizados de forma simples e direta.
Ler perfil completo → | Baixar Currículo (PDF) →